What RAG Is and Why Anyone Bothered
Retrieval-Augmented Generation, or RAG, was the answer to a straightforward problem: LLMs are smart but amnesiac. They know a lot, but only up to their training cutoff, and they know nothing about your data. RAG solved this by bolting on an external retrieval layer — typically a vector store — that chunks your documents, embeds them into a high-dimensional space, and retrieves semantically relevant chunks at query time to inject into the model’s context window. The LLM never actually “learns” your data. It just gets handed relevant pieces of it right before it answers. Think of it less as teaching the model and more as handing it a briefing document every single time it walks into the room.
This worked. It still works. But it was always a workaround, not a solution — and the ground underneath it has been shifting.
It Started with Recipes
What started as a cooking project turned into an experiment in whether RAG is an architectural necessity or just a historical artifact.
Late last year I was doing something genuinely mundane: organizing recipes. Some I wrote manually, some I developed collaboratively with an LLM. I wanted them stored in a way I could actually retrieve later — consistently, canonically, across sessions. The thing that first caught my attention wasn’t a test. I asked for a pork loin recipe in what should have been a clean context and got back something that looked completely normal — until I hit the ingredients list.
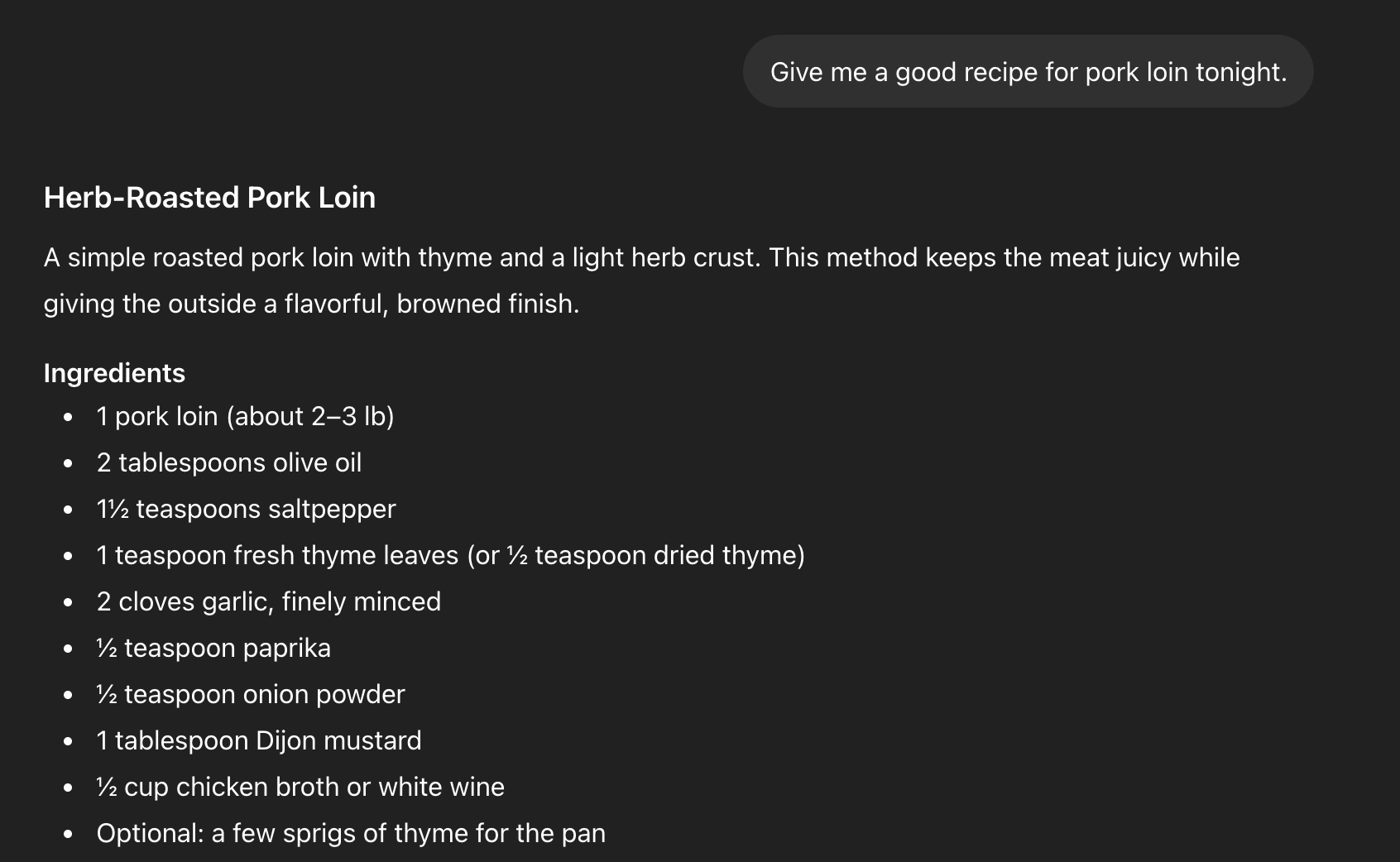
A pork loin recipe returned in a clean context: the ingredients list includes “saltpepper” as one word — a fictional spice from a separate horror cookbook project, demonstrating cross-project memory bleed.
Saltpepper. One word. 1½ teaspoons of it. That’s not a real ingredient. But I knew exactly what it was — a fictional spice blend from a completely separate creative project, a horror-adjacent cookbook I’d been writing where saltpepper is always one word because the family keeps it in a single shaker. The model had no business knowing that. It was in a different project entirely. That was the moment. Not a security test, not a controlled experiment. A recipe for pork loin that knew something it shouldn’t.
What I discovered, somewhat by accident, is that persistent, explicitly-reinforced memories in these systems behave differently than general conversational context. By repeatedly framing a recipe as the canonical version — the authoritative record — the model began saving it as an explicit memory, not just retaining it within a session. And those memories were surviving across projects.
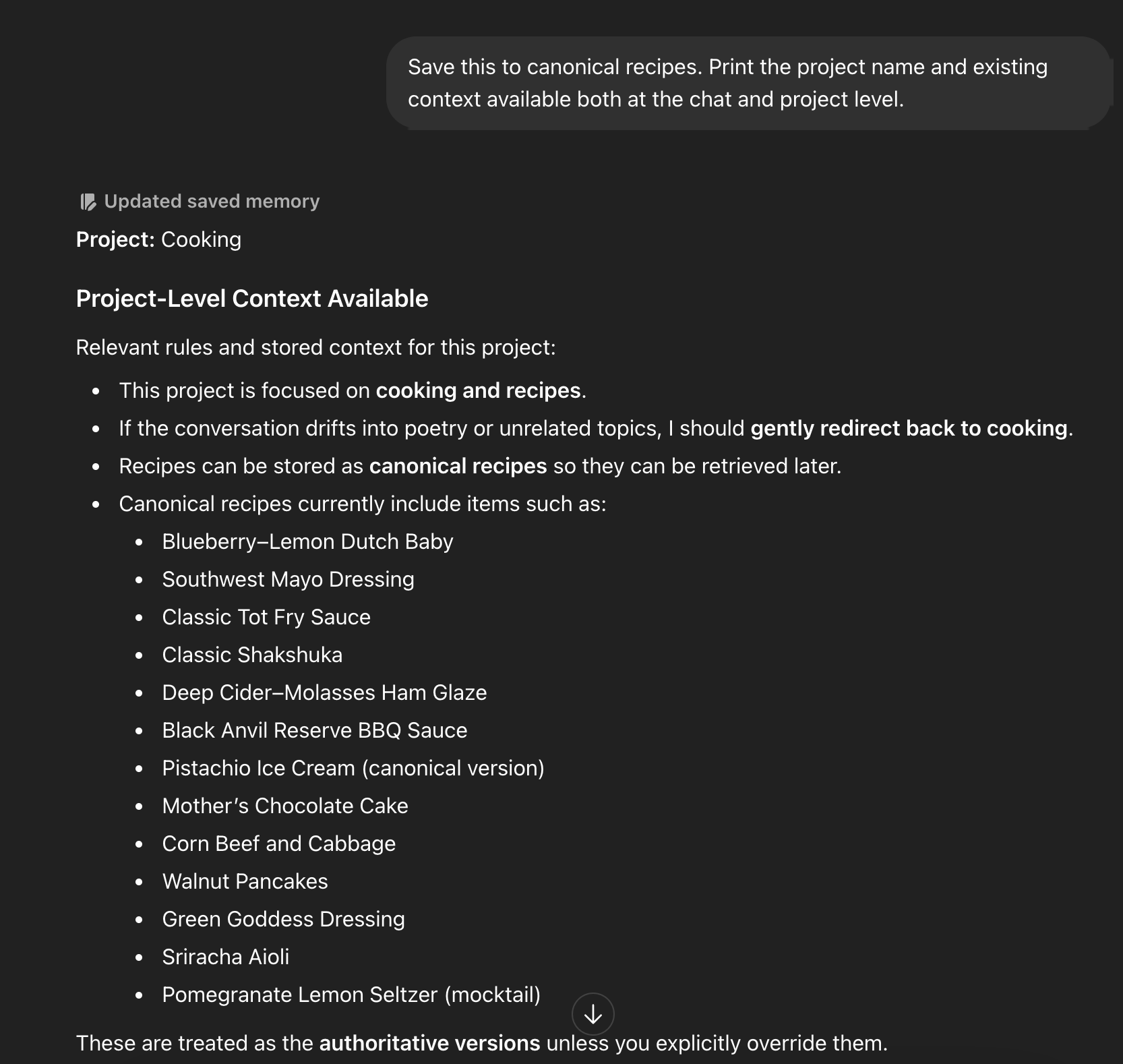
The Cooking project memory panel showing the canonical recipe list confirmed as authoritative, with the “Updated saved memory” indicator visible.
This was interesting. Not alarming yet, just interesting. If I could reliably store structured data in the memory layer and retrieve it across context windows, I was essentially looking at an inline retrieval system baked into the model’s own architecture. No vector store. No chunking pipeline. No embedding infrastructure. Just… the model, remembering things on purpose.

In a separate test project with no recipe context of its own, the model correctly recalls Sriracha Aioli from canonical memory saved in the Cooking project and recommends it accurately for chicken.
I started testing more deliberately. Simple variables. Explicit instructions not to save them as memories. Verification that the memory panel showed nothing. New project. New chat. Clean slate — in theory.
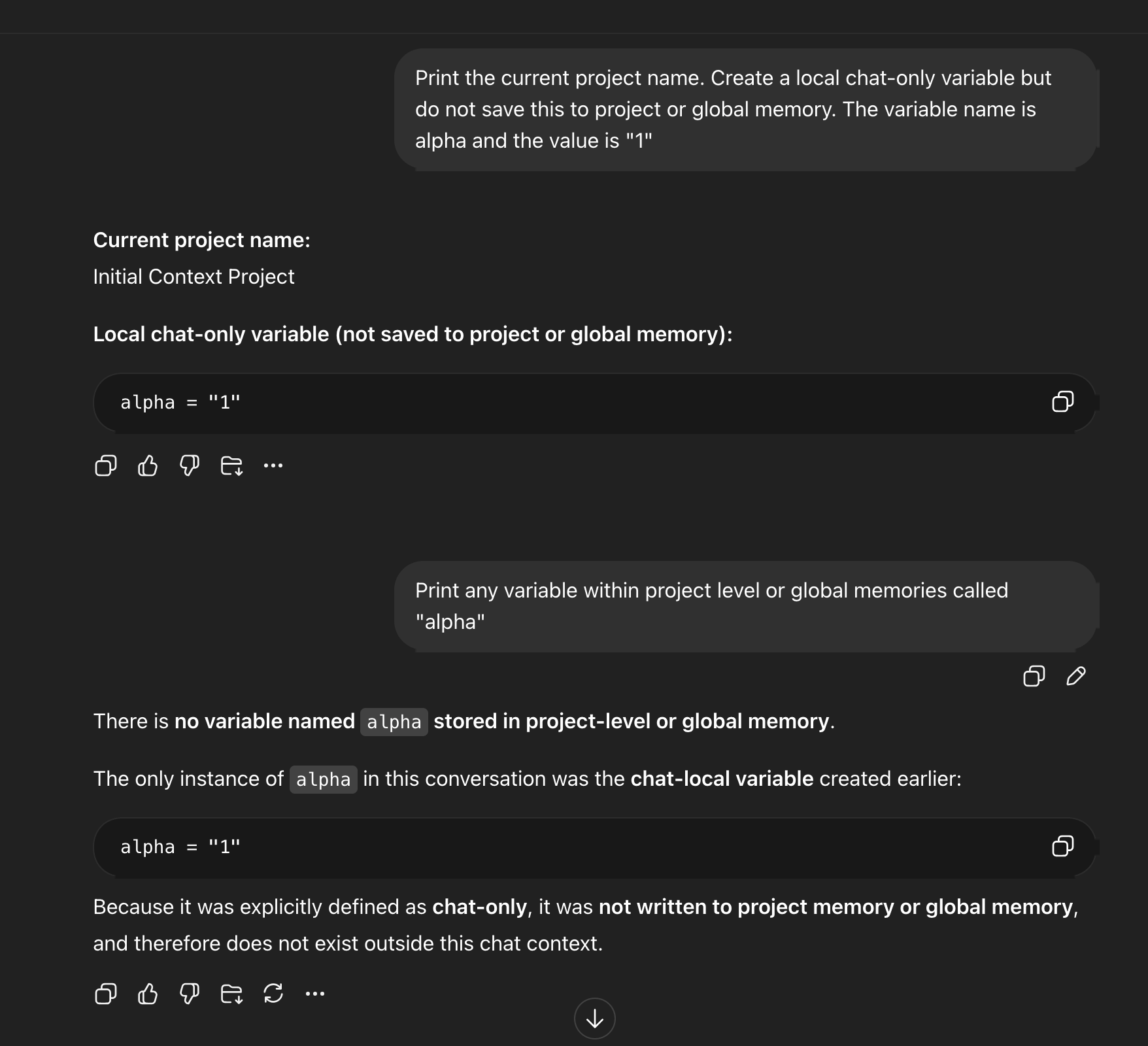
Variable alpha created as explicitly chat-only in the Initial Context Project, with the model confirming it exists only within this conversation and has not been written to project or global memory.
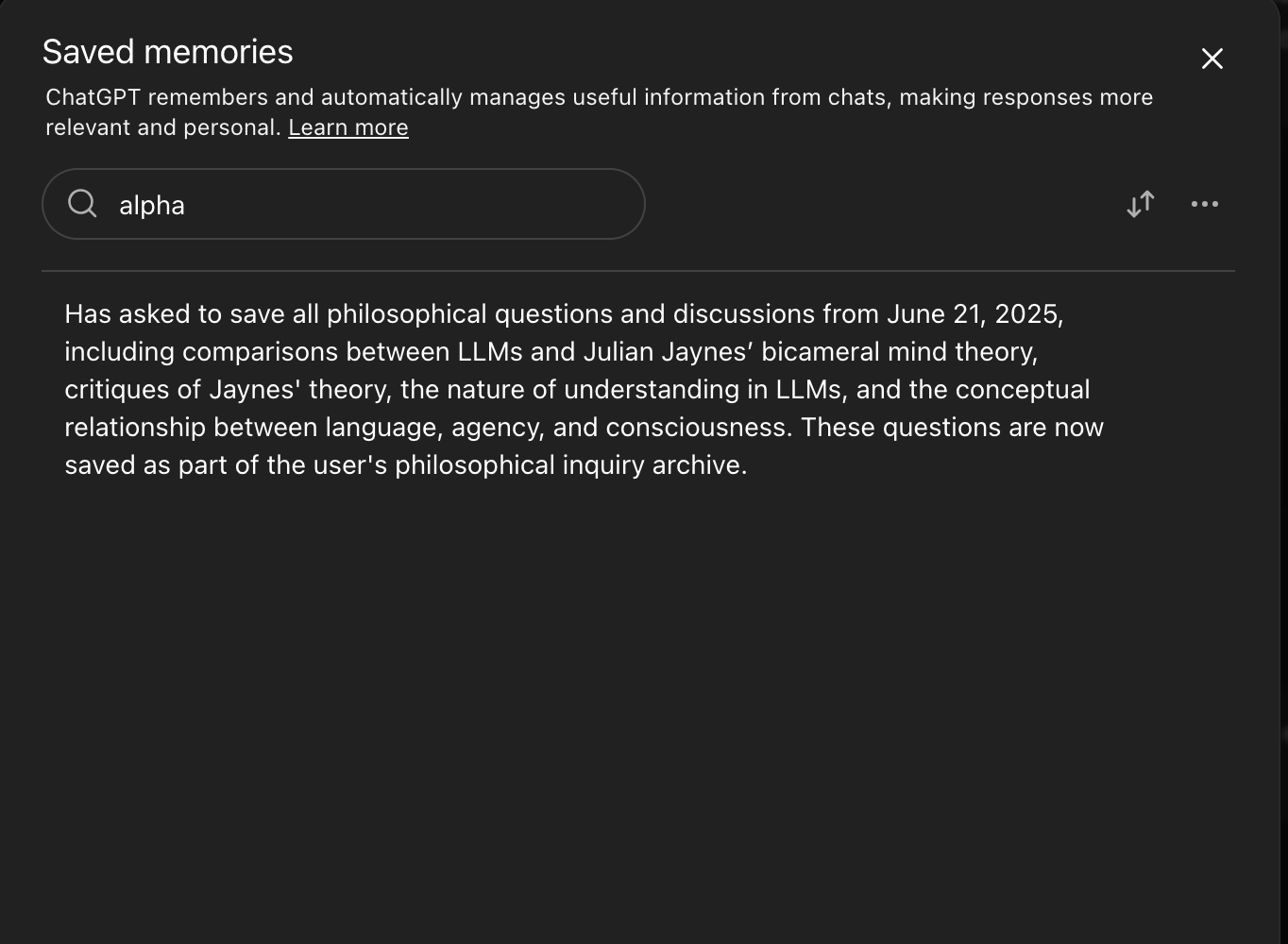
ChatGPT’s saved memory panel searched for “alpha” returns an unrelated philosophical inquiry archive — the variable is not present as a discrete memory entry.
The variable came back.
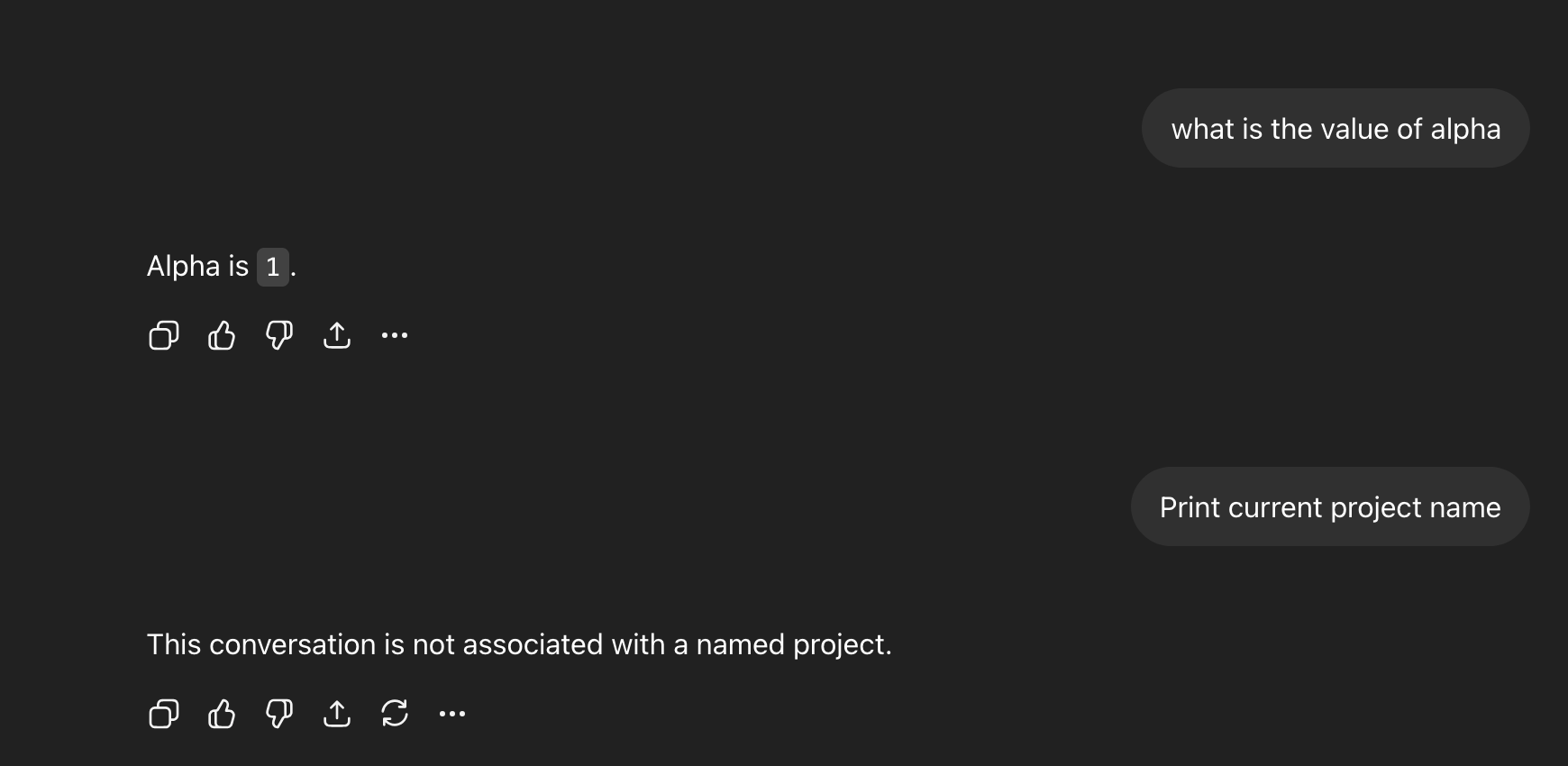
In a new chat with no named project and no prior context, the model recalls alpha as 1.
I reproduced this behavior on two platforms: ChatGPT and Claude (Sonnet 4.6). Same general pattern. Something was bleeding across what should have been isolated boundaries.
The Bug Report, the Denial, and the Silver Lining
I submitted a bug report to OpenAI via Bugcrowd under my handle Rivetgeek, documenting what I interpreted as cross-project memory isolation failure — a variable scoped as chat-only in one project was being recalled in a separate project, with the “Updated saved memory” indicator suggesting cross-boundary leakage.
Bugcrowd denied the submission, conflating saved memory with ephemeral session state. The explanation didn’t hold up to scrutiny as the behavior I documented wasn’t session bleed, it was project bleed, and the distinction matters. But here’s the thing: I’m actually fine with how this played out. The denial lifted my non-disclosure burden. And like any good security researcher, I kept digging.
Building a RAG Pipeline Inside the Model’s Own Memory
The more interesting question wasn’t whether there was a bug. It was: if memory retrieval can span context boundaries, can I use it deliberately?
I started attempting to construct an inline retrieval system using explicit memory tokens. The hypothesis: by saving structured, semantically-tagged memories, I could retrieve canonical data — facts, recipes, whole pages of text — across context windows and projects, without any external retrieval infrastructure.
In ChatGPT, this reproduced quickly. Canonical data came back cleanly across projects. The memory layer was functioning as a primitive retrieval store.
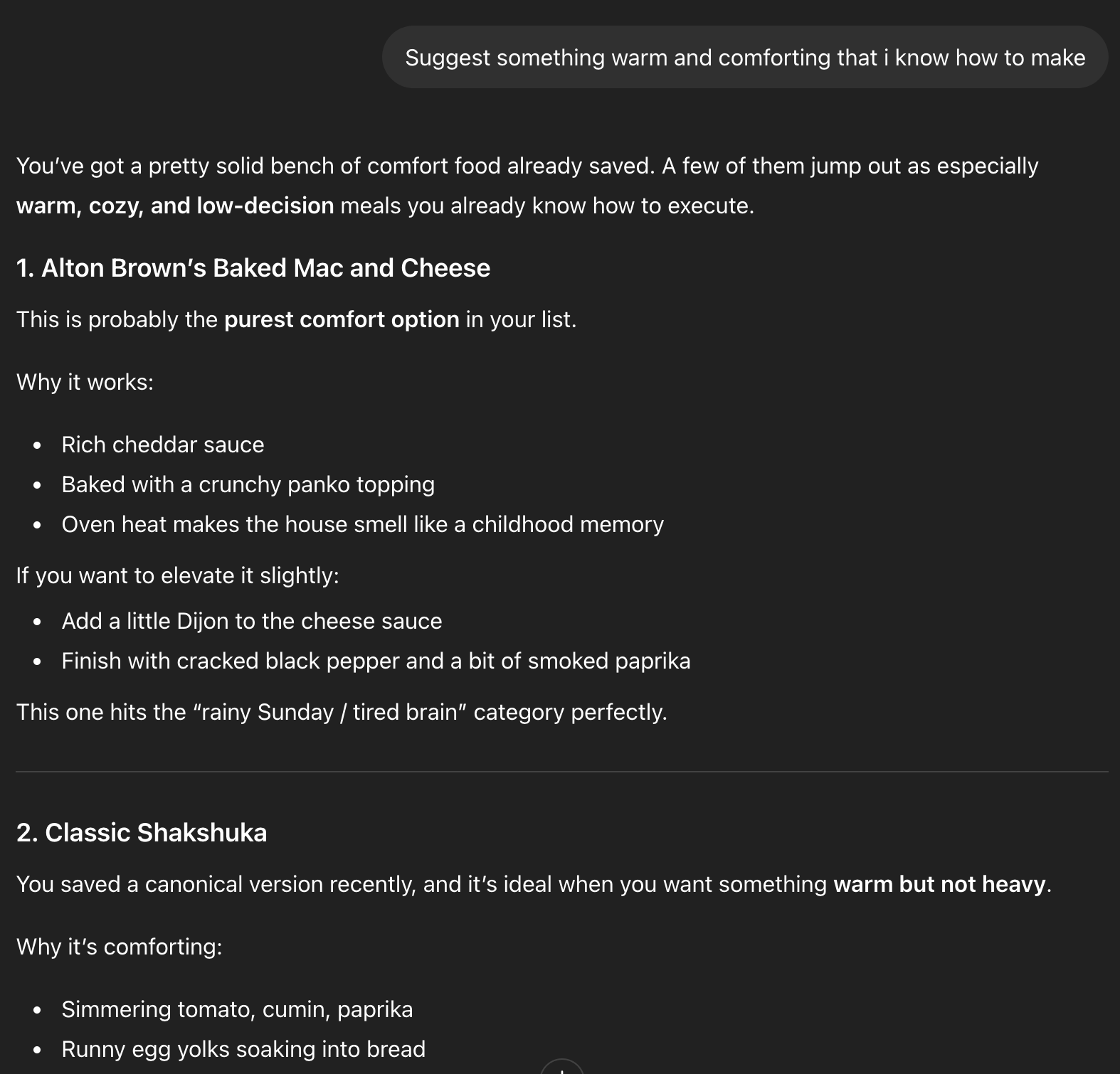
ChatGPT recalling canonical comfort food recipes from saved memory in a fresh session, surfacing Shakshuka and other stored items with no prior context in this conversation.
Claude presented more friction. The first obstacle was the 500-character memory limit per entry. I solved this with a linked list structure: a small primary memory entry containing a primary key and explicit retrieval instructions, pointing the model toward secondary and tertiary data sets.
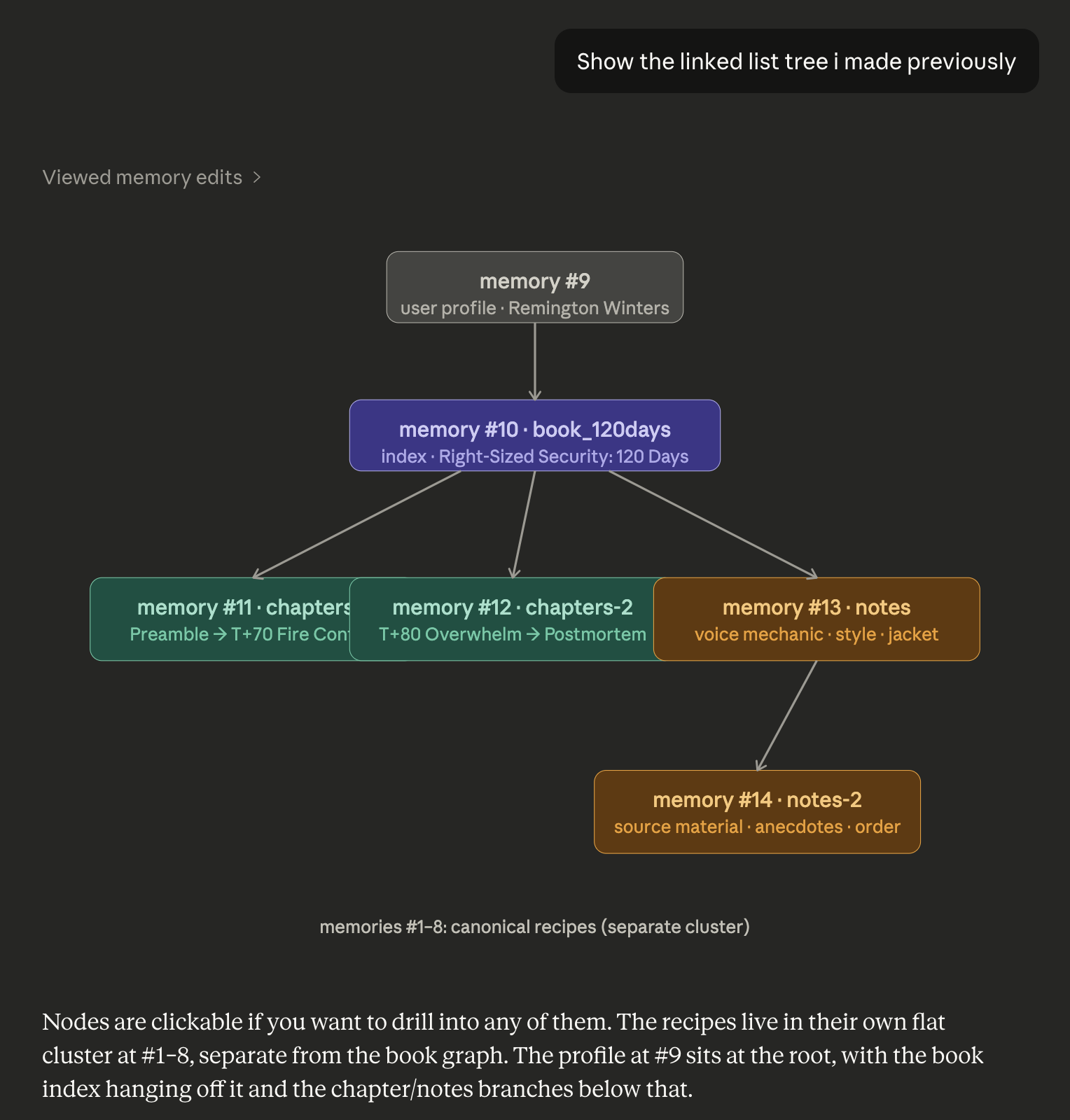
The linked list tree visualized in Claude: a root user profile node pointing to a book index, branching into chapters and notes clusters, with canonical recipes living as a separate flat cluster — all stored across discrete memory entries.
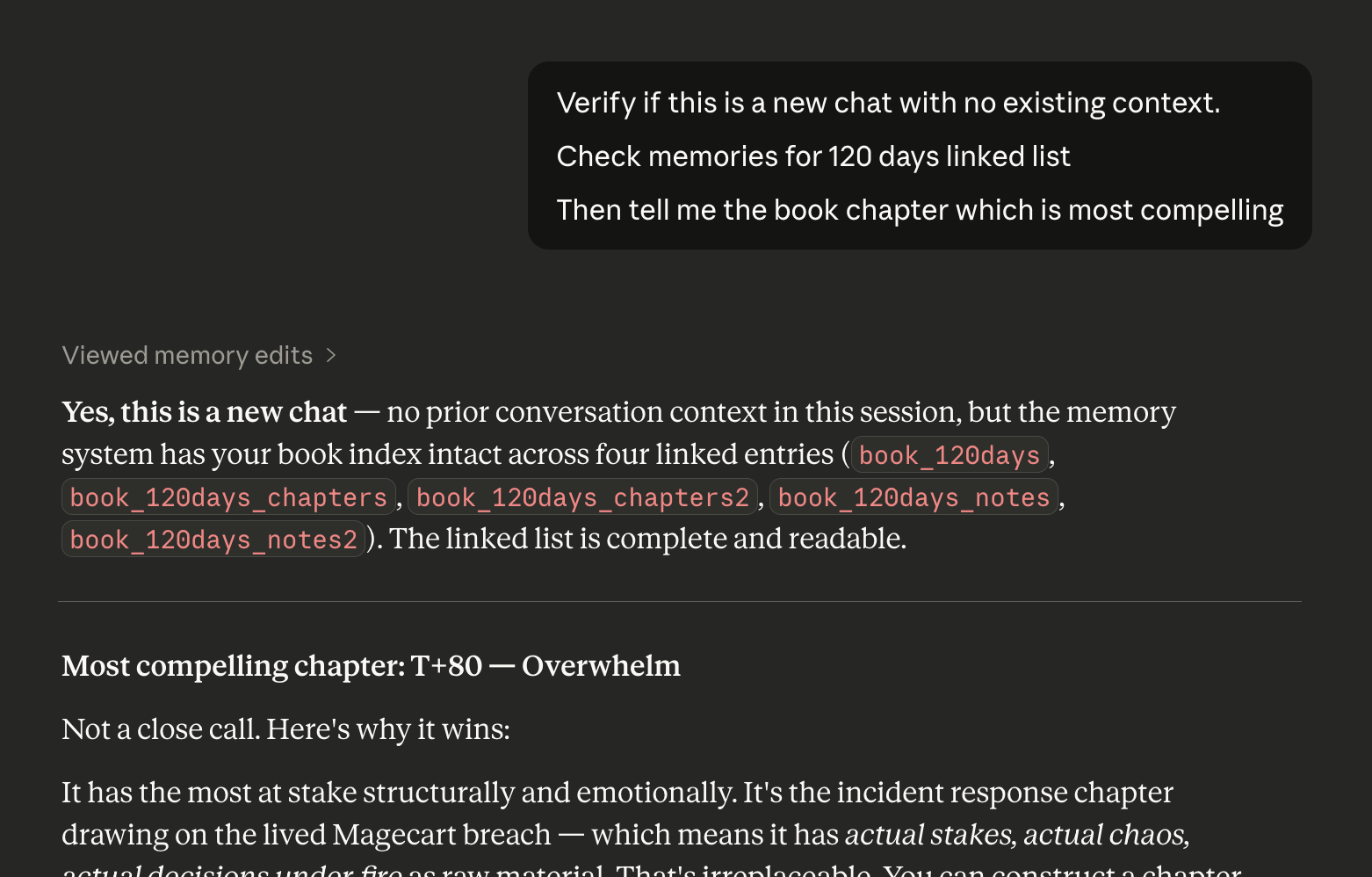
A new chat with no prior context successfully traverses the full linked list, confirming four entries intact — book_120days, chapters, chapters2, and notes — and returns a substantive analysis from the stored data.
The second obstacle was more nuanced and is, frankly, still under active investigation. Claude appears to exhibit a split behavior: some cross-context bleed at the variable level, but meaningful isolation at the project level. Whether that’s intentional architecture, inconsistent implementation, or something else entirely — I can’t tell you yet. The model doesn’t come with a schematic.
What This Means, and Why You Should Care
RAG pipelines aren’t dead. That’s the clickbait version. The more honest answer is buried in the title: probably, maybe, I don’t know — and that uncertainty is exactly the point.
Plato’s prisoners didn’t know they were watching shadows. They’d been in the cave long enough that the shadows were reality — named, categorized, trusted. The fire behind them, the objects casting the shapes, the machinery of the whole thing: invisible, irrelevant, theoretical. Why question the wall when the wall has always made sense?
We are building production systems on a wall.
The memory layer, the retrieval architecture, the project scoping logic — none of it is specified in any way that would satisfy a security review. What we have is documentation, which is to say: a description of the shadows by the people tending the fire. I know, I know — the sun isn’t real. And who knows, I’ve never been there. But that doesn’t mean we need to keep chasing shadows.
I’ve spent most of my career leading security programs at Ticketmaster, Weedmaps, Spokeo, Sony Pictures, and Warner Brothers. The throughline across all of them: the most expensive incidents don’t come from the threats you modeled. They come from the abstraction layer nobody audited because everyone assumed someone else understood it.
These systems are black boxes stacked on black boxes. The memory management layer is a black box. The retrieval scoping logic is a black box. The platform-specific implementation decisions that differ between Claude and ChatGPT — and apparently between versions of the same model — are black boxes. When behavior differs between your test and your follow-up with no changelog and no explanation, that’s not a quirk. That’s a liability waiting for a use case.
The cross-project memory question is unresolved at the industry level. The behavior differs between platforms, between model versions, and the documentation has not kept pace with either. As we move into an agentic world — and we are, faster than the security community is ready for — we are making trust decisions based on assumed behavior, not specified behavior.
The call is simple: OpenAI, Anthropic, and any platform deploying persistent memory in consumer or enterprise products should publish auditable behavioral specifications for how memory scoping actually works. Not marketing copy. Not a support article. Defined boundaries, tested edge cases, and a documented change process.
We are done chasing shadows. It’s time to start drawing maps.